
Много неща се промениха, откакто писах за последно по тази тема преди 5 години.
В един момент купих още един DL380e Gen8 с 32GB памет, повече ядра (два броя E5-2420) и място за големи дискове, но без caddy-та. Известно време бях с ESXi cluster, но не намерих много смисъл за моите нужди. Готино е да си местиш виртуалните машини от сървър на сървър, но бързо ми омръзна. След това вторият сървър стана Proxmox хост и си играх да уча и това. Имаше период, в който на Proxmox-а работеха Plex и много свързани с него неща. Само че липсата на дискретна видеокарта се оказа проблем, когато няколко пъти се наложи да се прекодират видеа заради невъзможността на клиента да гледа стрийма с пълна резолюция, та и това се пенсионира. Минах през толкова много софтуер, че няма шанс да си спомня всичко. Интересното е, че най-накрая флашнах iLO-тата на сървърите и мога да контролирам скоростта на вентилаторите. Това се оказа важно, след като се наложи да ги изместя в стаята, в която работя. Всички знаят, че излитащите изтребители звучат като HP сървър с вентилатори на 30%. Разбира се, ниските обороти доведоха до нуждата да лепя вентилатори по радиаторите на дисковите контролери. Няколко пъти получих и изключване, защото RAID картата на единия сървър скочи на над 100 градуса.
Старият QNAP (TS-459) изгоря по чуден начин през 2021-а. Един ден един от предпазителите беше паднал без видима причина. Вдигнах го и забравих за случая. Малко след това получих нотификация, че единият Nextcloud не работи. Нотификацията беше стандартното “Мишо, това не работи!”.
Машината, която хоства Nextcloud-а, беше пълна с логове за грешки по файловата система. Конкретният проблемен диск беше върху datastore, който беше mount-нат по NFS в ESXi. Беше забавно проследяване на проблема. Оказа се, че NAS-ът не отговаря на ping. Отидох при него и беше изключен. След като не реагира на натискането на копчето за включване, изтръпнах леко. В него бяха ~12TB неща, на които единствения бекъп към онзи момент беше RAID-а.
Отворих NAS-а и почнах да гледам къде какво се случва. Оказа се, че един кондензатор е изтекъл, дал е на късо и магическия пушек от захранването е излязъл навън.


В крайна сметка не загубих данни. Намерих приличен QNAP T-453A втора ръка, който и до момента работи (и е с външно захранване!). Новият NAS е и с 16GB RAM, което ми дава още място за игра. За миграцията използвах втория сървър, който към онзи момент си беше чист cold spare. Пуснах RAID контролера в HBA режим, сложих му Ubuntu и малко по малко изместих 12TB върху него. После ги местих към новия NAS. Всичко по гигабитова мрежа и терабитов стрес.
Сега
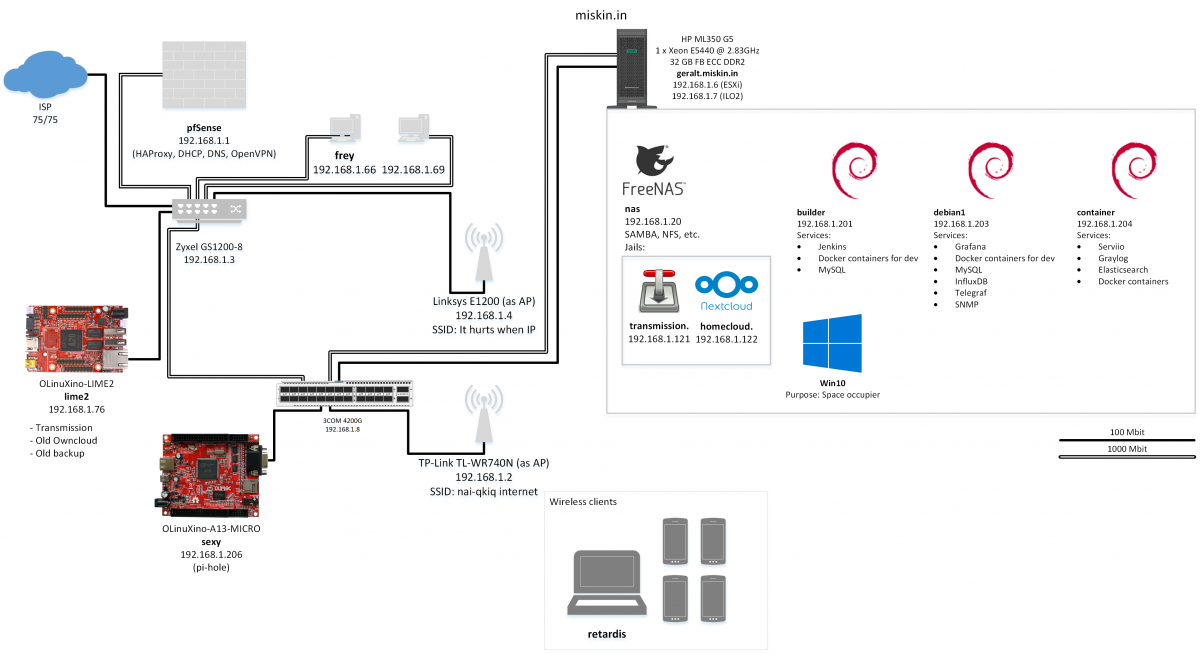
Основната промяна, поне в контекста на lab-а, е, че си купих къща, която довършвах сам в продължние на няколко години. Това ми даде възможност да направя много неща, които исках, точно както ги искам. Едно от тези неща беше да прекарам кабели за 10 гигабита мрежа навсякъде. Дори телевизорът в спалнята ми е с cat. 6a (flex, flex, но работи по WiFi).
Освен 10-гигабитовата мрежа друго, което исках, е да имам истински шкаф за техниката, за да може всичко да ми е подредено. Тъй като къщата не е по мой проект, няма истинско сървърно (засега) и се наложи да консолидирам всичката мрежова техника на високо в антрето, докато сървърите все още живеят в “рака”, който сглобих предния път.
Rack
Изкарах късмет и си купих този 12U рак от сайт, в който бяха забравили да вдигнат цената. Вдигнаха я веднага след поръчката ми.


(След снимката подредих кабелите. Честно!)
Монтирането беше приключение. Монтирах го сам. В един момент го държах на глава, докато бях върху стълбата. Не паднах. Мерих всичко точно много пъти и въпреки това се наложи да пиля малко от гърба, защото свредлото хвана леко накриво и дюбелът не можеше да влезе в предвидения за това отвор. Дори да бях пробил права дупка, пак щеше да се наложи да пиля, защото дюбелите са 10 или 12mm, а отворите на шкафа са по-малки.
Зад шкафа пробих стената и изкарах гофрирана тръба. Идеята е да изкарам мрежа по кабел навън в тази част. Мисля от другата страна на тази стена да сложа кутия, в която да са компютрите и релетата за автоматизацията на двора. Все още имам две OLinuXino-та, които биха свършили идеална работа. Към момента единствено излиза един водоустойчив DS18B20, с който следя температурата навън.
Вдясно се вижда кутия за предпазители (не бушони). В нея има един 24A, след който сложих Shelly Pro 4PM. Това Shelly засега служи само за следене на потреблението на мрежата. Останалите три канала са предвидени за автоматизация на осветлението навън. Отгоре се вижда стария UPS, който ползвах временно, докато намеря как да събера APC-то вътре. Вляво висят двете влакна оптика, по които идва интернетът. Първоначалната идея беше да използвам двете връзки, за да е по-бързо, но и само едната ми е достатъчна.
В момента в рака има следното, от долу нагоре: UPS, NAS, Raspberry Pi 4, мониторинг, суич, инжектор за едното AP, PDU, разклонител, рафт за ненужни неща, NVR, първия ми истински рутер (MikroTIk RB4011iGS+5HacQ2HnnD (накратко)), малко cable management, patch panel, много нетерминирани кабели, умен вентилатор и прах.
Не предполагах, че нещо ще ми хареса повече от pfSense, но MikroTik-ът ме впечатли много. Основно с това колко много имам да уча и колко много възможности ми дава за това. Върху него пуснах WireGuard, който замени OpenVPN-а от предния път. Настроил съм и NAT към Raspberry-то, което е входната точка отвън.
Raspberry-то върши най-важната работа след рутера. Върху него се търкалят: Home Assistant, AdGuard, HAProxy и fail2ban. През HAProxy изкарвам всичко, което искам да е изкарано и го ползвам за SSL termination на всички сървиси, за които имам домейни. В момента има дефинирани около 20 backend-а, голяма част от които сочат към Apache с виртуални хостове или Nginx, който също сервира различни услуги според домейна, source IP-то или URL-а.
Home Assistant
Друго важно нещо, което е свързано към pi-чето е Zigbee dongle-а. Така изглежда Zigbee мрежата преди да съм сложил всички неща, които подготвих за слагане:

В един момент реших, че колкото и да ми харесва да си правя устройствата с ESPHome, трудно ще бия леснотата, която дават готовите Zigbee играчки. Това, разбира се, не означава, че спрях да си правя такива. Последното, което започнах, е RFID управление за врата. Остава ми само да взема електронна брава, която да управлявам. За Zigbee устройствата използвам Zigbee2MQTT, което е един от малкото софтуери, които работят безпроблемно (след като имах мъки при подкарването).
Споменах умен вентилатор. Умен е, защото се управлява от едно ESP8266, което е програмирано с ESPHome. Така мога да го виждам в Home Assistant и да правя автоматизации според температурата в рака или да го управлявам ръчно:

Мониторингът в рака използва един от модулите, които правих за умната шамандура, а именно този с BPM180 и DHT11. Към тях добавих и вече споменатия Dallas DS18B20, който следи температурата навън. Тези сензори са свързани към друго ESP8266, което също е програмирано с ESPHome. Сложих му и един 7-сегментен дисплей, на който се въртят температурата и влажността в рака.

Home Assistant е безкрайна тема. Толкова ми харесва, че избирам уредите според това дали мога да ги интегрирам лесно. Използвам го за всичко, което може да се автоматизира. Като се комбинират готовите Zigbee решения с елементарното правене на автоматизации, решаването на “проблеми” става изключително лесно. Може би най-простия пример е лампата в пералното – просто качих един Sonoff SNZB-03 на вратата, сложих едно ZBMINIL2 в ключа и автоматизирането отне няколко клика. Вече няма как да забравя лампата в пералното светната ¯\_(ツ)_/¯.
Към момента най-много използвам управлението на климатиците и следенето на температурите. За офиса направих автоматизация, която да спира климатика, ако го забравя, след като свърша с работа, както и такава, която да го пуска, ако температурата падне под допустимата за китарите. Елементарни неща, които вдигат нивата на удобство с минимални усилия.
Тъй като мога да пиша прекалено много за Home Assistant, ще спра тук. Набира доста популярност последните години, та няма да кажа нищо нечувано. Може би ще пиша пак по въпроса, ако реша да споделя някоя custom интеграция.
Сървъри
Големите сървъри вече спят и са пенсионирани. Работата им пое стария десктоп (i7-4790k, 32GB RAM), на който сложих Proxmox и мигрирах виртуалните машини от ESXi. Миграцията се оказа лесна и с минимални драми.
Оставих три виртуални машини, които ми покриват всички нужди. На едната са всевъзможни сървъри (PostgreSQL, Redis, Rabbit, etc.), на другата работят NextCloud и transmission-daemon (за Linux ISO-та). Третата е просто docker host, който използвам за тестване на контейнери. Най-важното там е docker registry-то, което използвам за CI/CD на някои лични проекти.
Пенсионирах Jenkins и k8s. Вероятно скоро пак ще вдигна k8s cluster, защото имам идеи за нови играчки.
Използването на обикновен десктоп има доста плюсове, като по-малкото потребление на ток и по-малкото шум, но и странни минуси като липса на iLO. Засега нямам проблеми с consumer hardware-а, но все пак настроих бекъпи на нещата, които са ми важни. В някой бъдещ момент вероятно ще му сложа 10GbE карта, за да мога най-накрая да си ползвам бързата мрежа вкъщи. Друго, което смятам да сложа, е и дискретна видеокарта, която да ползвам за прекодиране на видео.
Блог
След близо 15 години на споделен хостинг, този сайт вече се хоства върху една малка машина в DigitalOcean. Същата малка машина, която вече почти 10 години прави повече, отколкото може да се очаква от малка машина.
Единствената причина да продължавам да се боря със споделени хостинги беше, че ми дават имейл без да се налага да го поддържам аз. Тъй като да поддържаш собствен мейл сървър е специална форма на мазохизъм, дълго време беше оправдано. След като Голяма Хостинг Компания Х купи хостинг провайдъра, който ползвах и започна да вкарва “добрите” си практики, реших, че е време да се мигрирам. Проблемът с имейла го реших с Google.
Бързо наближавам възрастта, в която искам основните ми неща да работят без да прекарвам излишно време в оправяне на вече решени проблеми.
























{kind=link}
{kind=link}