Category: Tech
-

Lab 3.0 – The Downsizening
Много неща се промениха, откакто писах за последно по тази тема преди 5 години. В един момент купих още един DL380e Gen8 с 32GB памет, повече ядра (два броя E5-2420) и място за големи дискове, но без caddy-та. Известно време бях с ESXi cluster, но не намерих много смисъл за моите нужди. Готино е да…
-
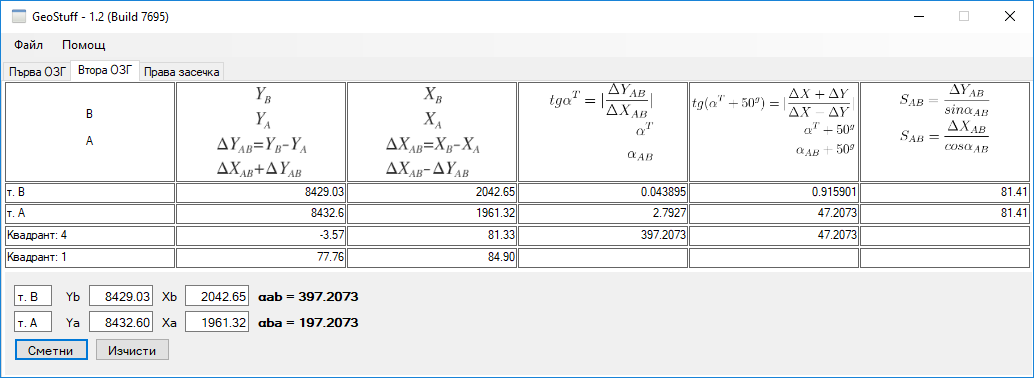
GeoStuff-1.2
Програмата за решаване на геодезически задачи е най-успешния ми личен проект в дългосрочен план. Написах я по някое време в гимназията, защото ми беше писнало да смятам едни и същи еднообразни сметки по безброй пъти. Оказа се, че е полезна на много хора и вече 11 години след първата си версия продължава да се тегли…
-
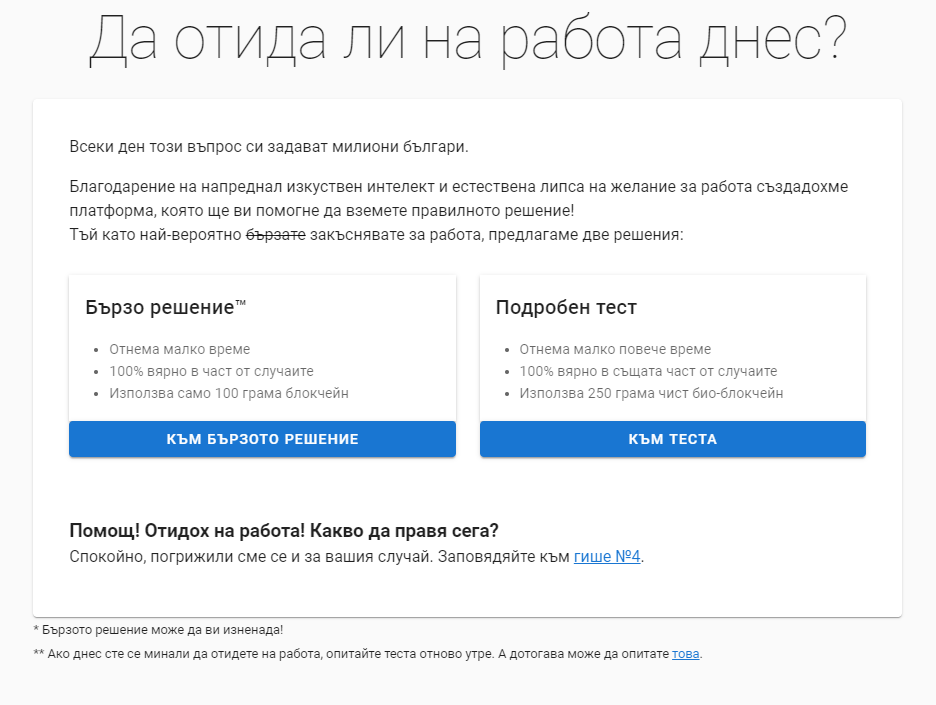
Да отида ли на работа днес?
Програмистите, както много други работещи в офис, сме несериозно племе. Благодарение на това някои от нас прекарват доста време в оплакване от работата (често оправдано) и основно чакане да свърши. Преди 5-6 години написах страница с таймер до 18:00, която се хареса на доста колеги. След това ѝ добавих и таймер до деня в месеца,…
-

Lab 2.0
Не очаквах нещата да се развият толкова бързо. Мрежата вкъщи се разрасна с няколко нови попълнения, като двете основни са HP ProLiant DL380e Gen8 и QNAP TS-459 Pro II. Малко след като се оплаках, че старият сървър ми струва излишно много пари за ток, попаднах на добра оферта в eBay и в момента основният ми сървър…
-

Amazon
В края на миналия месец бях на onsite интервю в Amazon за позицията Software Development Engineer, която щеше да ме закара в офиса им във Ванкувър. Ставаше въпрос за екипа в AWS, който работи по Step Functions. Не ме харесаха. Тъй като нямат практиката да обясняват защо са отказали на кандидат, мога само да гадая…
-
Нова версия на приложението за чистене на линкове
Може да е малко нарцистично, но приложението ми за махане на глупости от URL-и ми влиза в употреба постоянно и му се радвам много. Когато не ми се налага да разкарвам tracking параметрите ръчно, споделянето става по-лесно, което пък увеличава честотата на спама, който пръскам насам-натам. Win-win. Малко след като пуснах първата версия, в приложението…
-
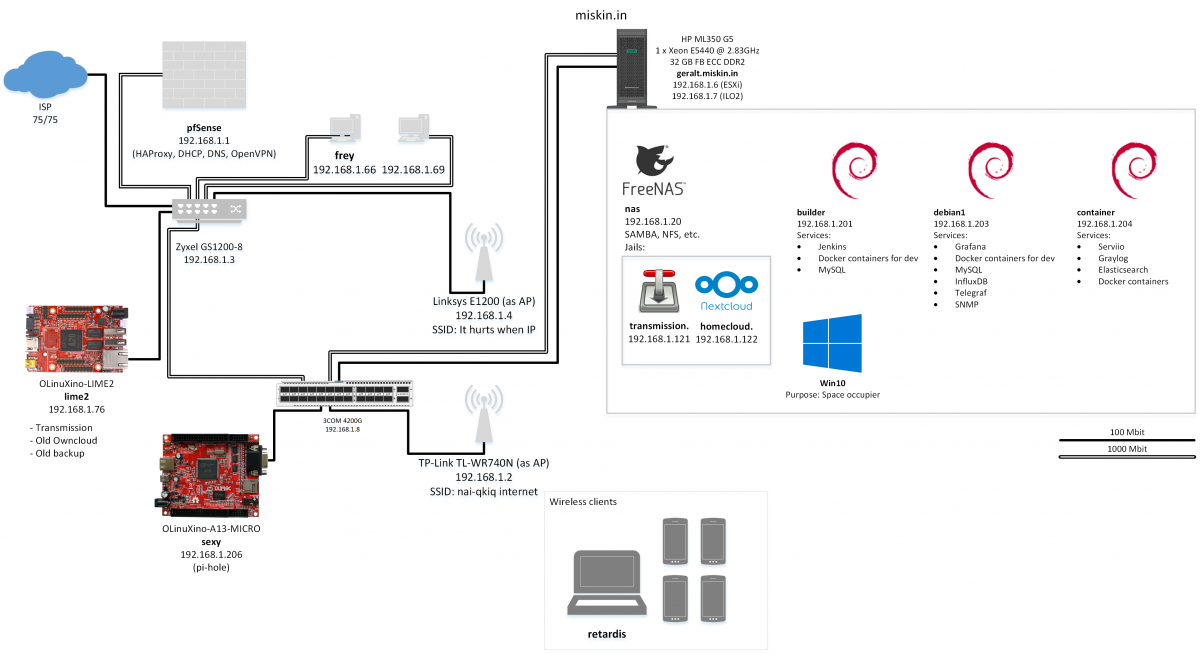
Lab
Update: Lab 2.0 Както писах преди, от доста време искам да имам физически сървър вкъщи, който да си администрирам и гавря, както реша. В началото на годината по щастливо стечение на обстоятелствата това се случи и в момента се радвам на един HP ProLiant ML350 G5. Това се оказа несвършващ проект и от януари не…
-
Използване на Java Reflection API за мързелива “документация” на response кодове
В единия от страничните проекти използваме REST за комуникация между фронтенда (Vue) и бекенда (Spring Boot). Приложението е сравнително просто и пиша бекенда сам и за документация на REST-а използвам Swagger. Това значително услеснява имплементацията на фронтенда откъм информация за endpoint-и и кой какво може да очаква като заявка/отговор. Тъй като в процеса на работа…
-
NAS
Откакто научих какво е NAS, искам да сглобя едно такова, за да имам място специално за информацията, която ми е важна. Освен това има много неща, които са ми интересни и искам да си играя с тях, но е неоправдано да не са виртуализирани. Преди десетина години вкъщи се появиха няколко едва работещи компютъра. От…
-
Share link decrapifier
Приложението добавя елемент в менюто за споделяне на Android, който копира споделяния текст, премахвайки частите от него, които се използват за допълнително следене. Неща като “utm_source”, “fbclid” и др. изчезват. Така, например, адресът “https://www.instagram.com/p/BppzKrmneqd/?utm_source=ig_share_sheet&igshid=jywYcSpOs8008“, който генерира Instagram от share бутона си, ще стане “https://www.instagram.com/p/BppzKrmneqd/“. Може да се свали от Google Play от тук: Предистория Не…