Tag: Java
-

Amazon
В края на миналия месец бях на onsite интервю в Amazon за позицията Software Development Engineer, която щеше да ме закара в офиса им във Ванкувър. Ставаше въпрос за екипа в AWS, който работи по Step Functions. Не ме харесаха. Тъй като нямат практиката да обясняват защо са отказали на кандидат, мога само да гадая…
-
Нова версия на приложението за чистене на линкове
Може да е малко нарцистично, но приложението ми за махане на глупости от URL-и ми влиза в употреба постоянно и му се радвам много. Когато не ми се налага да разкарвам tracking параметрите ръчно, споделянето става по-лесно, което пък увеличава честотата на спама, който пръскам насам-натам. Win-win. Малко след като пуснах първата версия, в приложението…
-
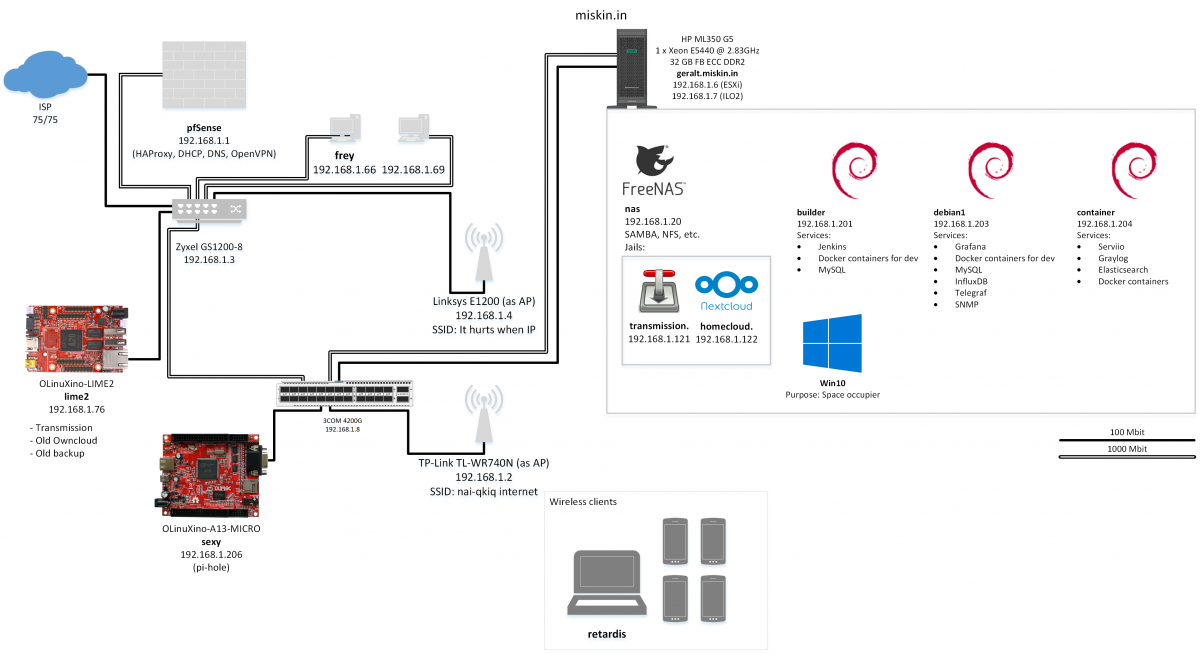
Lab
Update: Lab 2.0 Както писах преди, от доста време искам да имам физически сървър вкъщи, който да си администрирам и гавря, както реша. В началото на годината по щастливо стечение на обстоятелствата това се случи и в момента се радвам на един HP ProLiant ML350 G5. Това се оказа несвършващ проект и от януари не…
-
Използване на Java Reflection API за мързелива “документация” на response кодове
В единия от страничните проекти използваме REST за комуникация между фронтенда (Vue) и бекенда (Spring Boot). Приложението е сравнително просто и пиша бекенда сам и за документация на REST-а използвам Swagger. Това значително услеснява имплементацията на фронтенда откъм информация за endpoint-и и кой какво може да очаква като заявка/отговор. Тъй като в процеса на работа…
-
Програмата за геодезически задачи и за Android
Тъй като виждам, че доста често се тегли desktop версията на програмата за геодезически задачи, реших да я напиша набързо и за Android. Все пак, след като имаше версия за MIDP 2.0 телефони, защо не и за нещо по-модерно 🙂 Оказа се забавна играчка и смятам да добавя още доста неща, но първо ще трябва…
-
Състезания
Да го свърша това, докато не ме е домързяло пак… През последните седмици бях на няколко състезания, две от които национални по информационни технологии – едно в Благоевград и едно тук, в Търново. Дойде им времето да бъдат описани. Не взех нищо от двете състезания, но не се и очакваше. Моят “проект” беше писан за…
-
2010-03-16
Неща, за които трябваше да пиша преди седмица. Първо да кажа за Sonisphere – няма да ходя. Мина лимита на хора, които мога да изтърпя да ме питат. Bummer. Миналата събота бях на втория кръг от олимпиадата по английски. Пак обичайните лесни неща. Този път беше интересно. Диктовката беше от някоя от Хари Потър книгите,…
-
Как да си пусна java програма?
Е, писна ми разни хора да ме питат как да си подкарат разни java програми. Ето го обяснението на нереално сложния процес на подкарване на програма, писана на java:
-
![Програма за решаване на втора основна задача в геодезията [обновена + версия за Android]](https://img.chilyashev.com/2009/12/main_screen-940x198.png)
Програма за решаване на втора основна задача в геодезията [обновена + версия за Android]
GeoStuff е програма за решаване на основни геодезически задачи за Windows и Android. Повече подробности и линкове за сваляне има на страницата на програмата: https://chilyashev.com/geostuff/. Тази публикация е оставена тук с историческа цел, но тъй като виждам, че все още има много посещаемост, оставям само линка към страницата с последните версии информация.
-
Безполезна програма за генериране на честоти с java
Ето това е труда на 5-минутно умуване и игра с java-та. “Програмата генерира честота със зададено цяло число. Времетраенето е от 0.000… до 1 секунда (някога може да си поиграя да го направя и повече). Няма ограничение за честотата. И докато сме на темата за честотите, веднага заявявам, че не поемам никаква отговорност за повреди,…